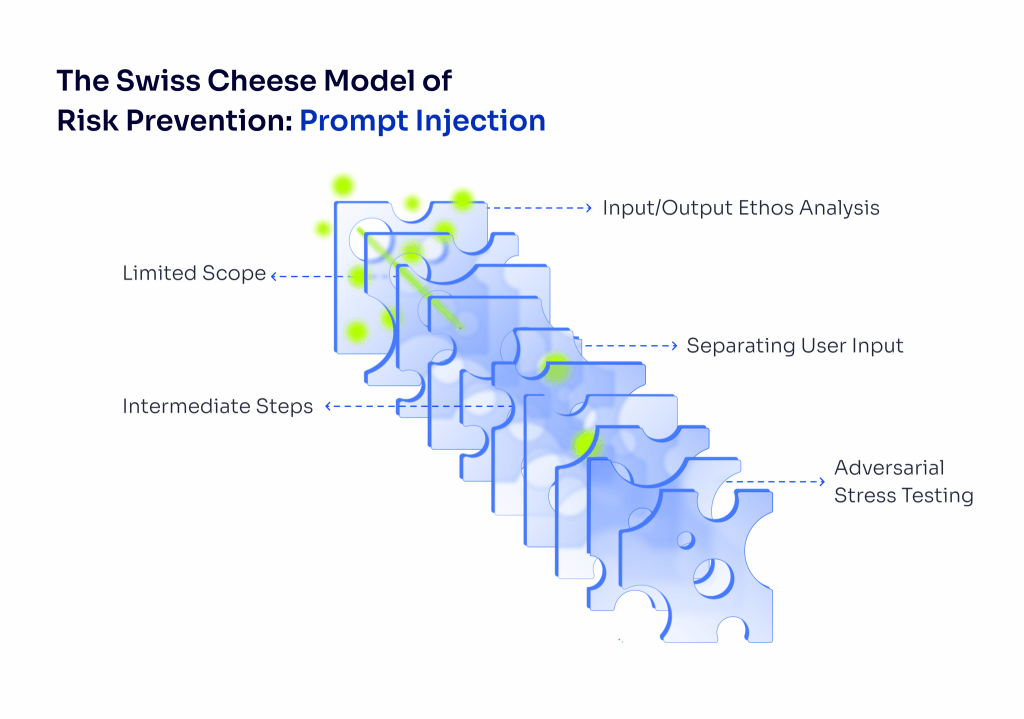
Remember little Bobby Tables?
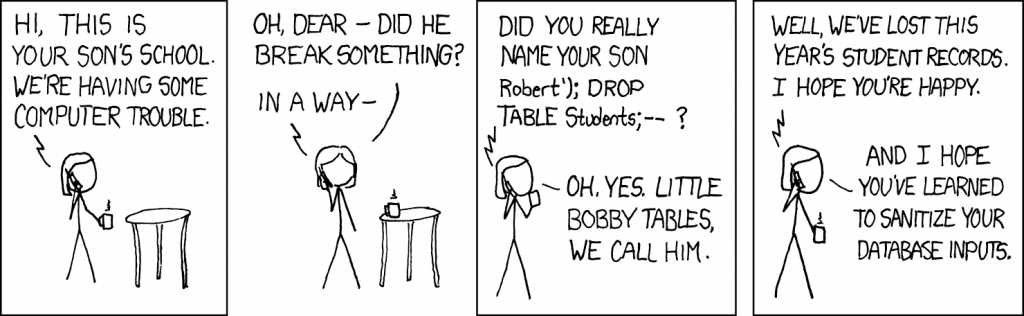
He’s all grown up now.
What is prompt injection?
Prompt injection is a bit like a sneaky trick that tries to make a Large Language Model (LLM) do something harmful or unexpected. Imagine you’re using an app that responds to what you type because it’s powered by AI. Well, prompt injection is when someone tries to get around the rules of that app and make the AI do something it’s not supposed to—like spill secrets or bypass restrictions.
It’s actually a lot like an old hacking technique called SQL injection. With SQL injection, people used to break into databases by slipping in special characters or commands where they shouldn’t be. It worked because the system couldn’t tell user input from actual instructions. The good news is, SQL injection is mostly a solved problem now—developers learned to sanitize user inputs so they can’t mess with code. But prompt injection? That’s a whole new challenge.
This issue first started getting attention in 2021 and 2022, but it’s only become a major concern recently as AI-driven tools have exploded in popularity. One example from 2023 involved Chevrolet. They decided to put chatbots on their dealership websites to help answer customer questions, but some clever users got the chatbot to offer cars for just $1—just by asking it the right way! The media called the person who shared it a “hacker,” but it wasn’t a typical hack; it was exploiting a weakness in how the chatbot was trained to respond.
The situation got even trickier legally. In British Columbia, a court recently ruled that companies are responsible for what AI agents on their websites say. This was because a chatbot on Air Canada’s website gave incorrect information to a customer about getting a flight refunded. The customer took Air Canada to court and won, setting a legal precedent that the company is on the hook for the AI’s mistakes. So, it’s not just a technical problem anymore—it’s a legal one too.
So, how do we deal with this tricky and potentially costly problem? That’s the big question we’re all trying to answer. At 123linux.com, we’re bringing together some of the best minds in the AI industry—including the talented engineers at Algolia—to compile an ultimate guide on how to reduce the risks of prompt injection. We’ll be sharing insights from our in-house AI experts, as well as findings from interviews and deep research conducted by our experienced team. Stay tuned as we break down how to stay one step ahead of this growing security challenge!
Before diving into solutions, it’s smart to take a step back and think about the bigger picture—do you even need an LLM in the first place? There’s a piece of wisdom from a volunteer construction group that applies here: the safest way to deal with risk is to eliminate it entirely. If you can’t eliminate it, then you reduce it, and only after that do you turn to engineering solutions to manage it. Makes sense, right? It’s better to remove a problem altogether than to spend time and resources trying to minimize its effects.
With that in mind, consider whether an LLM is truly the right tool for your needs. Be honest—if LLMs weren’t the current “in” thing, would you still be using one? Sometimes it’s worth rethinking if LLM technology is necessary or if there’s a safer, more focused alternative that suits your needs just as well. Here are a few questions to help you evaluate:
Are you using an LLM to answer a specific set of support questions? If so, there might be a simpler, safer option. For example, you could use a vector search algorithm to match user questions to answers. Vectors are mathematical representations of concepts, generated from words, that can be used to determine how similar two ideas are.
For a quick crash course, consider checking out Grant Sanderson’s illustrated video from his YouTube channel, 3Blue1Brown—it’s a great introduction to how vectors work, even for beginners. In short, vectors can be thought of like arrows pointing in a certain direction in space, where that direction actually represents meaning. By performing math on these vectors, you can quantify relationships between ideas.
LLMs use this same concept under the hood, converting your prompts into vectors that they then process to generate responses. But here’s the cool part—if you’re just trying to find the closest match to a dataset, you can skip using an LLM and go straight to working with vectors directly. With a well-trained vector model, you can create “vector embeddings” for every support question you have, and when a user asks something, you generate a vector for that query. By measuring the “distance” between the query vector and the stored vectors, you can effectively find the best match and return the correct answer.
This approach can be more reliable, easier to manage, and less prone to unexpected issues like prompt injection—all while giving you much more control over the output. It might not be as trendy as using a full-blown LLM, but for some applications, it’s the perfect fit for getting the job done safely and effectively.
A little side note here—this vector search algorithm is actually what powers Algolia’s main product, NeuralSearch. Now, this article is meant to be informative and not a marketing pitch, so we’re not going to spend time singing the praises of NeuralSearch here. Instead, if you’re interested, feel free to check out this blog post where you can learn more about it and draw your own conclusions.
Because we’ve got some solid experience with vector-based technology, we plan to dive deeper into these kinds of solutions in future articles. So, if you’re curious about practical alternatives to LLMs or just want to expand your toolkit, stick around—there’s a lot more to come!